A friend asked me today if I could help extract some data from Fyple. Let’s first analyze the data we need to scrape and how it’s structured.
Table of contents
Open Table of contents
Understanding the Data Structure
The company listing page is relatively simple, consisting of three main components: the red box shows regions and primary/secondary categories, the green box contains the company listings, and the yellow section can be considered as tertiary categories, which are also visible in the company details.
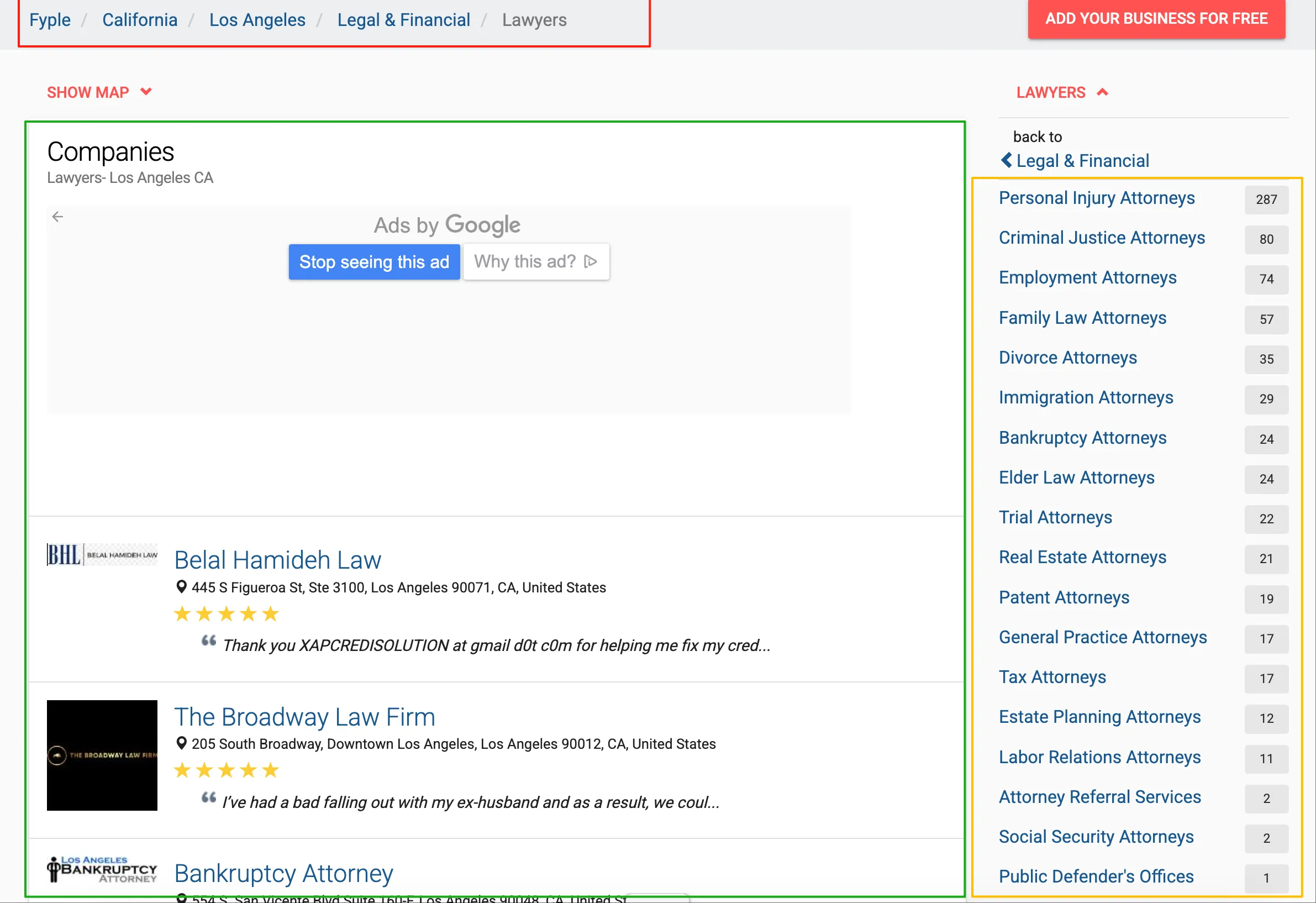
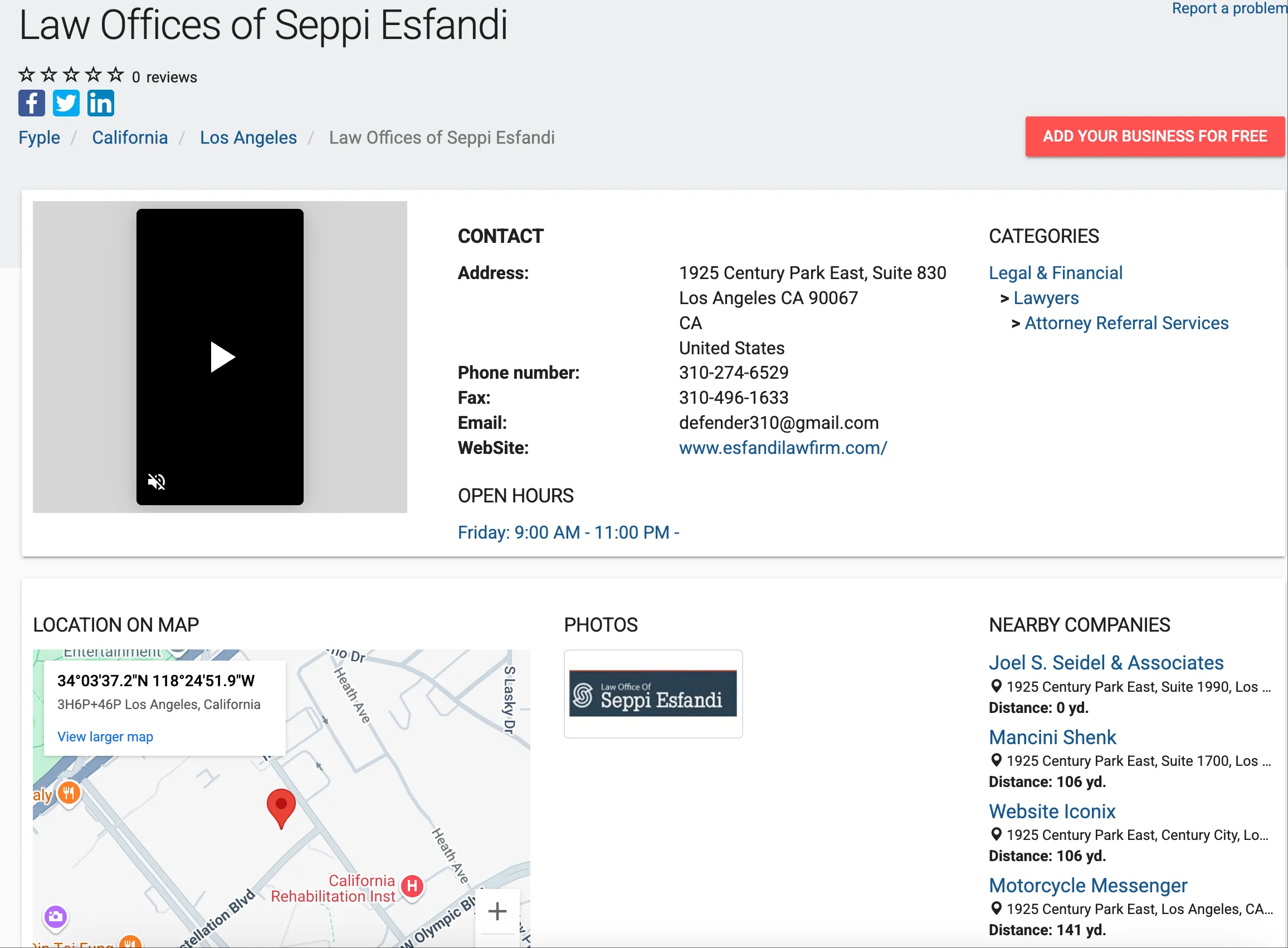
After examining the page and API, there’s both good news and bad news:
Good news: No significant protection mechanisms - easy to scrape Bad news: No API available - we have to parse HTML
AI-Assisted HTML Parsing
Parsing web page structures is perfect for AI. First, Region/City/Categories are fixed elements that can be hardcoded. We’ll have AI save this data directly to local files.
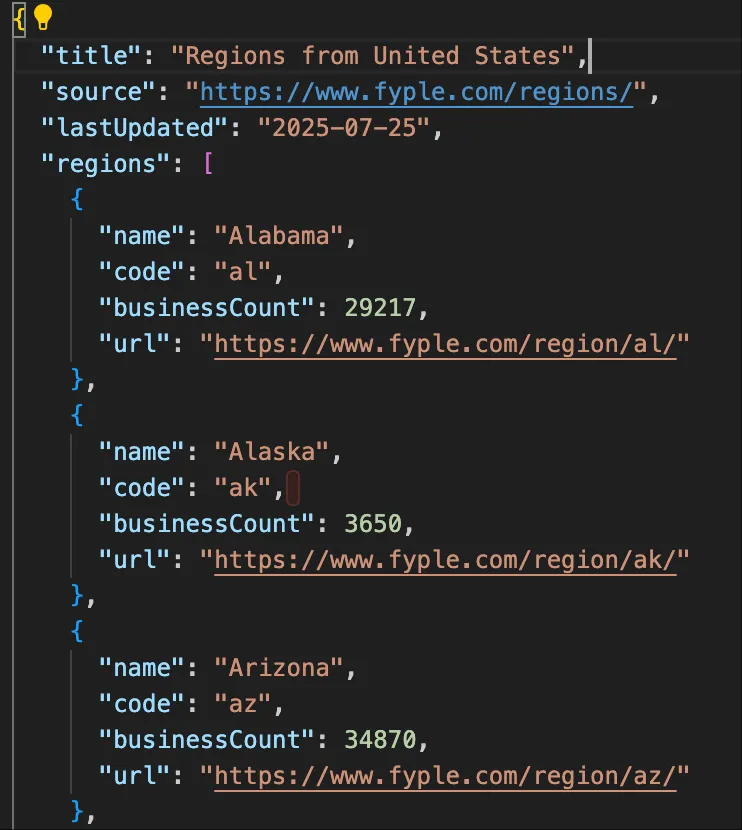
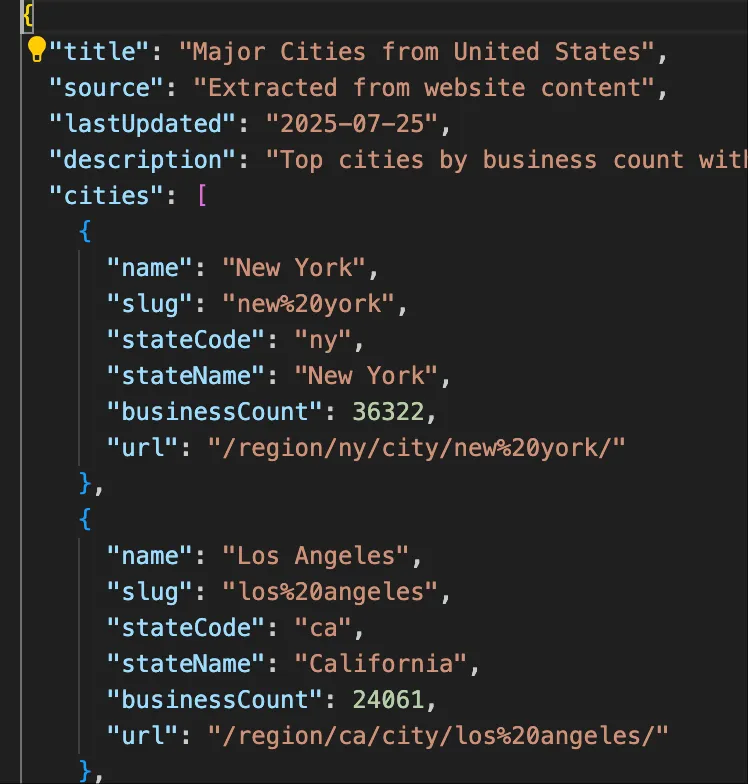
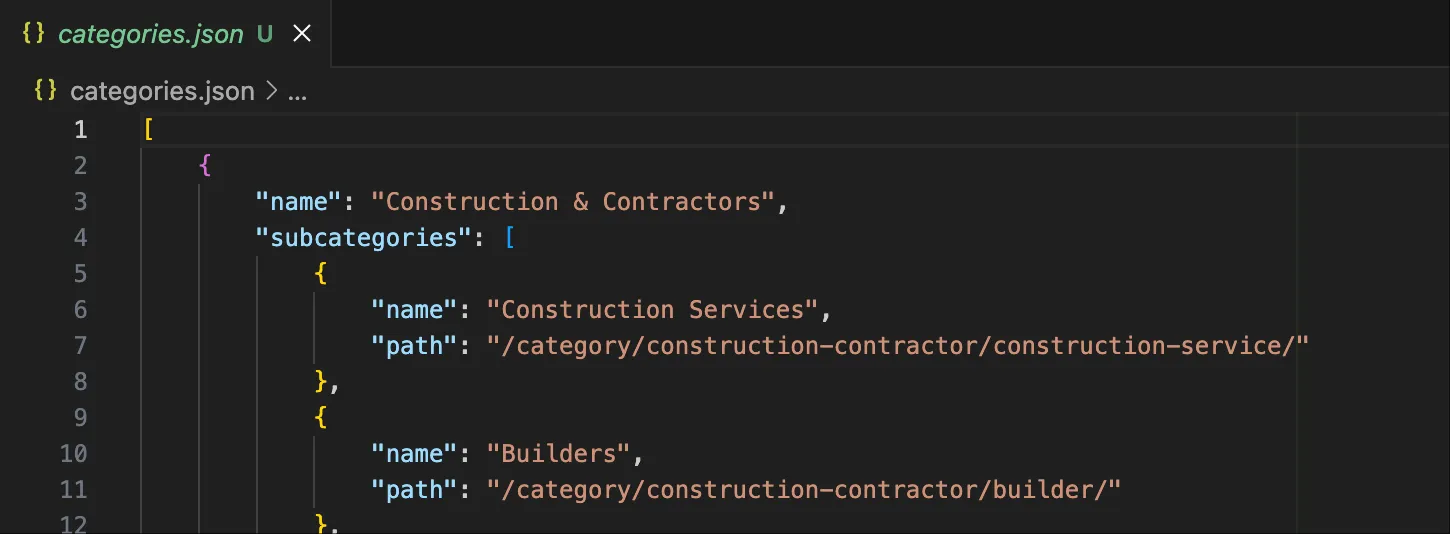
Processing Categories with Gemini CLI
Since the webpage with primary and secondary classifications is quite large, we used the free Gemini CLI to process this file. As you can see, it handled the task quite well.
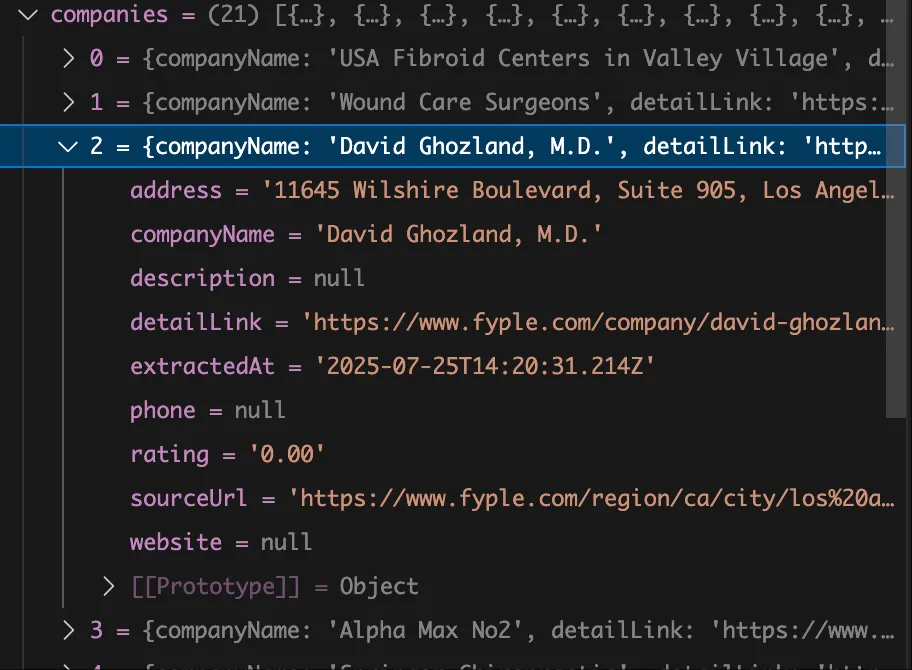
Batch Data Extraction
Now we can start batch extracting data by constructing URLs. The company listing URL pattern follows: region + category, like this:
https://www.fyple.com/region/ca/city/los%20angeles/category/health-beauty/doctor-and-clinic/physician/We continued using AI to write the extraction code. After some debugging, it worked without major issues. Now we need to extract detailed information for each company.
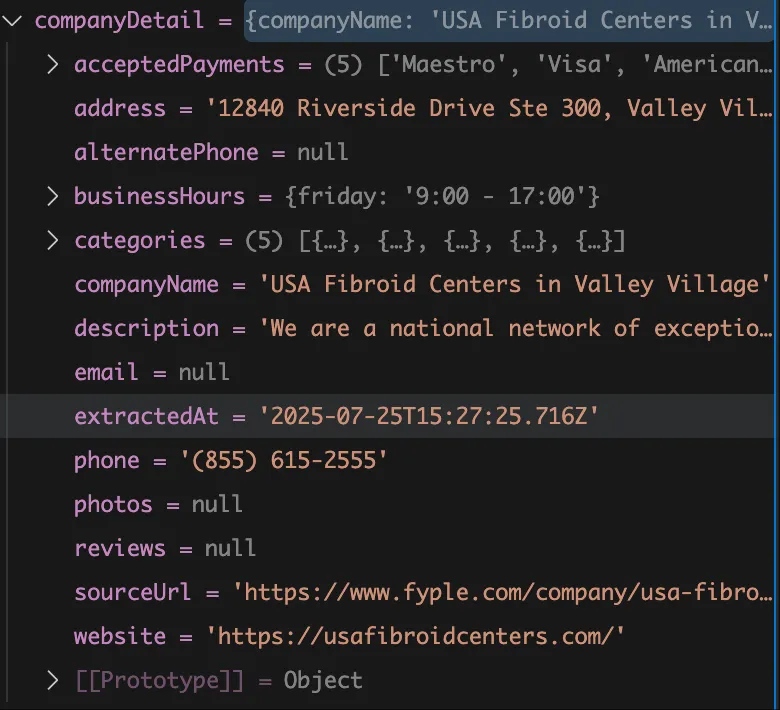
Extracting Company Details
We fed the company detail page URLs to AI to extract the required information.
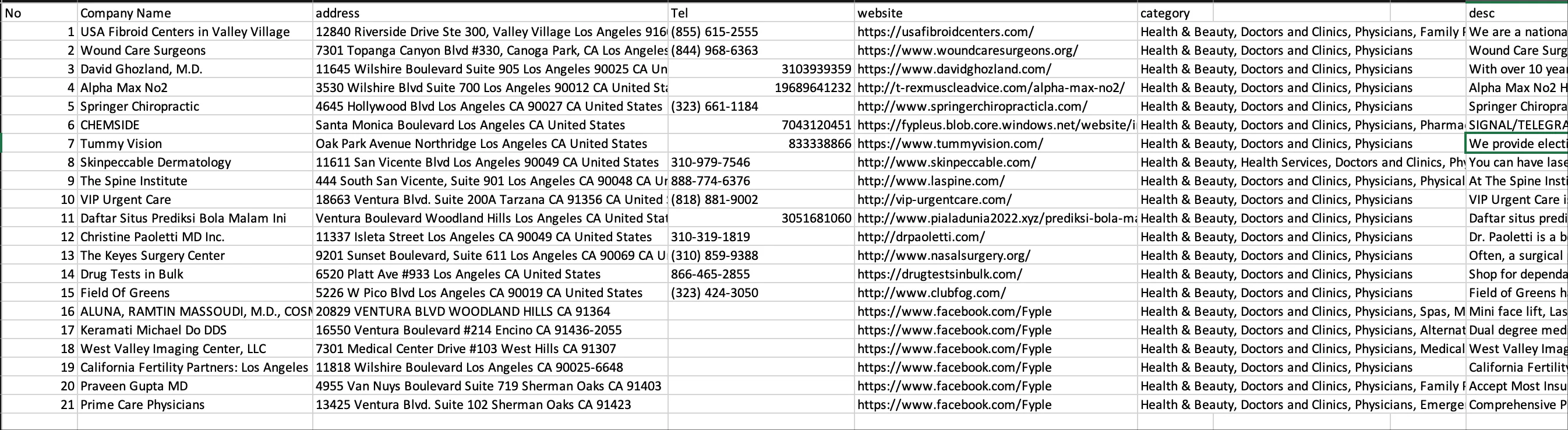
Data Export
Finally, we need to export all this information to Excel format.
Conclusion
The remaining task is to scrape all the content systematically. This approach demonstrates how AI can significantly streamline web scraping workflows, from initial data structure analysis to final data export.
Key Takeaways
- AI-Assisted Development: Leveraging AI for HTML parsing and code generation significantly reduces development time
- Structured Approach: Breaking down the scraping process into manageable components (regions, categories, listings, details)
- Tool Selection: Using appropriate tools like Gemini CLI for processing large datasets
- Data Pipeline: Creating a complete pipeline from scraping to Excel export
This method can be adapted for similar directory-style websites that require bulk data extraction.